
前言
在之前的学习中,只知道索引这个东西的存在,没有系统的了解过,使用中也是现去搜索引擎上去搜索使用,知其然而不知其所以然,今天写下这篇文章系统的学习和总结一下,希望对之后的工作能够有所帮助。
什么是索引?
索引就像书的目录和书的正文之间的关系,它能够帮助人们快速地得到正文的位置。而在Mysql中,索引的定义是这样的:
索引(Index)是帮助Mysql高效地获取数据的一种数据结构。
所以,我们可以知道:索引的本质是一种数据结构。它按照特定的数据结构将数据放在索引文件中,方便我们快速查找数据。并且会占据磁盘的物理空间。
索引的类型
FULLTEXT
全文索引,目前只有MyISAM引擎支持,它只能够在char、varchar、text列上可以创建全文索引,它并不是和MyISAM一起诞生的,它的出现是为了解决WHERE name LIKE "%word%"这类针对文本的模糊查询效率低的问题
HASH
由于Hash的唯一性及其键值对的结构,很适合作为索引。Hash可以一次定位,不需要像树形结构那样逐层查找,所以效率很高。但是,这种高效只有在“=”和“IN”条件下高效,对于范围查询、排序及组合索引效率仍然不高。
BTREE
BTREE索引就是将索引值按照一定的算法存入一个树形的数据结构(二叉树),每次查询都从树的root节点开始,依次遍历node,获取leaf,这是Mysql里默认和常用的数据结构。
RTREE
RTREE在Mysql中很少使用,仅支持地理数据类型,Mysql基本不用,我们这里也不做讲解。
索引的种类
- 主键索引:也就是Mysql中的主键,必须唯一且没有空值,因此在主键上的索引也是唯一索引。一个表上的唯一索引可以有多个,但主键只有一个。
- 普通索引:与唯一索引类似,但允许值重复。
- 唯一索引:顾名思义,索引必须唯一,其中唯一索引可以出现空值。(即表中某个字段建立了唯一索引,那么这张表中一个值只能出现一次。)
- 组合索引:也叫复合索引,INDEX(A,B,C)。
索引操作
- 创建索引
- 创建普通索引:
CREATE INDEX index_name ON table_name(col_name) - 创建唯一索引:
CREATE UNIQUE INDEX index_name ON table_name(col_name) - 创建普通组合索引:
CREATE INDEX index_name ON table_name(col1_name,col2_name) - 创建唯一组合索引:
CREATE UNIQUE INDEX index_name ON table_name(col1_name,col2_name)
- 创建普通索引:
- 通过修改表结构创建索引:
ALTER TABLE table_name ADD INDEX index_name(col_name) - 创建表时直接指定索引:
CREATE table_name(
ID INF NOT NULL,
col_name VARCHAR(255) NOT NULL,
INDEX index_name (col_name)
);
- 删除索引:
DELETE INDEX index_name ON table_name
存储引擎中索引的实现
什么是存储引擎
数据库存储引擎是数据库底层软件组件,数据库管理系统使用数据引擎进行创建、查询、更新和删除数据操作。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎还可以获得特定的功能。
MySQL 5.7 支持的存储引擎有 InnoDB、MyISAM、Memory、Merge、Archive、Federated、CSV、BLACKHOLE 等。可以使用SHOW ENGINES语句查看系统所支持的引擎类型,默认为InnoDB引擎,其它的我们不做讲解。感兴趣的小伙伴可以自己下去了解一下。
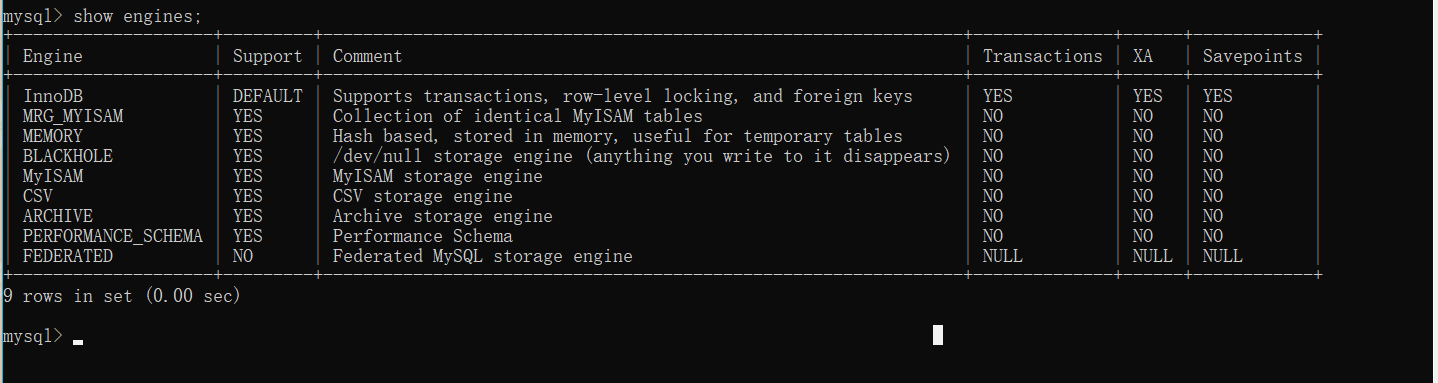
Support 列的值表示某种引擎是否能使用,YES表示可以使用,NO表示不能使用,DEFAULT表示该引擎为当前默认的存储引擎。
在上面我们讲了索引的不同类型,那么存储引擎和索引有什么关系呢?首先
- 在Mysql中,索引是在存储引擎中实现的。
- 不同的存储引擎可以支持不同的索引类型。
- 不同的存储引擎对同一种索引类型它的实现方式可能是不同的。
InnoDB存储引擎
在InnoDB引擎中,索引使用B+树实现,它有两种类型。
- 聚簇索引,在InnoDB中,Mysql中的数据是按照主键的顺序来存放的,那么聚簇索引就是按照表的主键拉构造一棵B+树,叶子节点存放的就是整张表的行数据。同时,由于表中的数据只能按照一棵B+树排序,因此一张表只能有一个聚簇索引。
- 非聚簇索引,根据表中的字段定义一个索引,会根据这个索引再次创建一棵B+树.因此, 我们每加一个索引,就会增加表的体积, 占用磁盘存储空间。

上图所示的就是一个聚簇索引,可以看到根节点和子节点是不存储数据的,只有叶子节点存储数据,这也是B+树的特性。

这张图展示的是一个非聚簇索引,我们可以看到:在叶子节点中存储的不是需要的行数据,而是一个索引值,当我们查询时,这个字段上如果有索引,那么会先查到这个字段的索引值,然后通过聚簇索引去拿到具体的数据。
注意
InnoDB引擎中,每增加一个索引,都会新增一个非聚簇索引,也就是一棵B+树。每棵B+树都会占据存储空间,而且每次插入数据,索引越多,你需要维护的B+树越多,导致性能下降。所以,索引不能够乱加,需要合理的使用。
以上。

